
안녕하세요.
이번에는 N+1 문제를 다루어 보았습니다. N+1 문제는 JPA를 사용하면 자주 만날 수 있는 문제이지만 자칫 잘못하면 예상치 못한 곳에서 N+1 문제를 만날 수 있다고 생각해요. 따라서 문제의 원인을 머릿속에 두고 테스트케이스를 통해 원하는 결과가 잘 나오는지 확인해 보는 습관을 길러보도록 합시다!
모든 소스 코드는 https://github.com/lkimilhol/tistoryblog 에서 확인 할 수 있습니다.
저는 유저와 유저가 가지고 있는 컴퓨터를 개념적으로 표현하였고 유저들은 다수의 컴퓨터를 가질 수 있도록 연관관계를 맺었습니다.
결국 유저와 컴퓨터는 1:N의 관계를 가지게 됩니다!
먼저 유저 클래스를 보도록 하겠습니다.
1. N+1 구현하기
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL)
private List<Computer> computers = new ArrayList<>();
public User() {}
public User(String name) {
this.name = name;
}
public void addComputer(Computer computer) {
computer.setUser(this);
computers.add(computer);
}
public List<Computer> getComputers() {
return computers;
}
}Computer.java
@Entity
public class Computer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private User user;
public Computer() {}
public Computer(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setUser(User user) {
this.user = user;
}
@Override
public String toString() {
return "Computer{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
컴퓨터는 내용을 확인 하기 위 해 toString을 오버라이드 하였습니다!
다음은 유저가 가진 컴퓨터를 조회하는 UserService를 보도록 하겠습니다.
@Service
@Transactional(readOnly = true)
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public List<String> findComputerNamesRepository() {
return findComputerNames(userRepository.findAll());
}
private List<String> findComputerNames(List<User> users) {
List<String> computerNames = new ArrayList<>();
for (User user : users) {
computerNames.addAll(user.getComputers().stream()
.map(Computer::getName).collect(Collectors.toList())
);
}
return computerNames;
}
}유저는 다수의 컴퓨터를 가질 수 있습니다. 우리는 findComputerNamesRepositry라는 메서드를 통하여 모든 유저의 컴퓨터를 조회하도롣 하였습니다!
결과가 어떻게 나오는지 테스트를 해볼까요? 테스트 코드를 작성해봅니다.
@SpringBootTest
class UserTest {
@Autowired
private UserRepository userRepository;
@Autowired
private UserService userService;
@BeforeEach
void setup() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User("유저" + i);
user.addComputer(new Computer("컴퓨터" + i));
users.add(user);
}
userRepository.saveAll(users);
}
@DisplayName("연관관계 확인")
@Test
void find() {
List<String> computerNames = userService.findComputerNamesRepository();
assertThat(computerNames.size()).isEqualTo(10);
}
}유저 10명에 대하여 각각의 컴퓨터 한 대씩 가질 수 있도록 하였습니다. 과연 테스트코드는 어떻게 동작하게 될까요?

일단 유저에 대한 조회 1건이 발생하였습니다. 저 조회를 통하여 유저 10명의 데이터를 가져왔겠군요!
그렇다면 아래 10건의 select는 무엇을 의미할까요?
바로 유저 조회를 통해 가져온 데이터 10건에 대하여 컴퓨터를 조회하고 있는 것입니다.
즉, for 문을 통하여 생성한 유저 10명에 대하여 하나하나 컴퓨터를 조회하고 있는 것이지요.

바로 이 문제를 N+1 문제라고 합니다.
현재 10명의 유저에 대하여 10건의 추가 조회를 하였어요. 그렇다면 유저가 100000000명 이라면 어떻게 될까요?
2. 해결 방법은?
두 가지 방법을 말해볼까 해요.
첫 번째는 fetch join 입니다.
fetch join이란 JPQL에서 제공하는 성능 향상 쿼리인데요. fetch join을 이용하여 join 쿼리를 만들 수 있습니다.
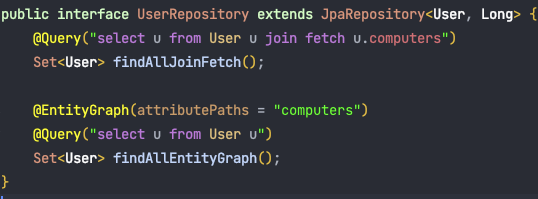
UserRepository.java
@Query("select u from User u join fetch u.computers")
List<User> findAllJoinFetch();다음 구문을 UserRepository에 직접 구현하였어요. 그리고 해당 메서드를 통하여 데이터를 가져와 보도록 하겠습니다.
UserService.java
public List<String> findComputerNamesByJoinFetch() {
return findComputerNames(userRepository.findAllJoinFetch());
}UserService에 위와 같은 메서드를 추가하였어요. 그리고 테스트 케이스를 작성하였습니다.
@DisplayName("연관관계 확인 - join fetch")
@Test
void findJoinFetch() {
List<String> computerNames = userService.findComputerNamesByJoinFetch();
assertThat(computerNames.size()).isEqualTo(10);
}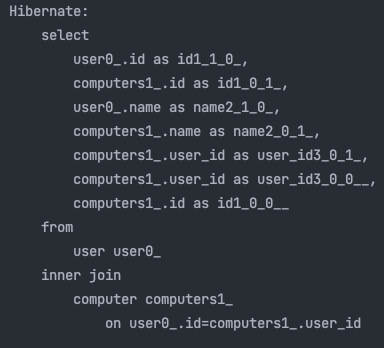
보시는 바와 같이 select는 1건으로 모든 조회를 마쳤습니다!
두 번째 방법은 Entity Graph를 이용하는 것입니다.
Entity Graph란 Entity를 조회할 때 연관 된 Entity까지 모두 조회하는 기능입니다!
UserRepository.java
@EntityGraph(attributePaths = "computers")
@Query("select u from User u")
List<User> findAllEntityGraph();이렇게 메서드를 추가하였습니다. 마찬가지로 테스트 케이스를 실행시켜 보도록 합니다!
UserService.java
public List<String> findComputerNamesByEntityGraph() {
return findComputerNames(userRepository.findAllEntityGraph());
}아래 테스트를 추가합니다!
@DisplayName("연관관계 확인 - entity graph")
@Test
void findEntityGraph() {
List<String> computerNames = userService.findComputerNamesByEntityGraph();
assertThat(computerNames.size()).isEqualTo(10);
}과연 결과는 어떻게 될까요?
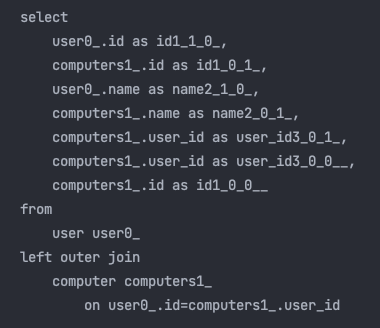
마찬 가지로 한건으로 모두 조회를 마쳤네요!
두 가지 방법은 모두 1건으로 join을 통해 데이터를 가져올 수 있어요. 하지만 다른 점이 하나 있네요.
join fetch는 INNER JOIN을 실행 한 반면 Entity Graph방식은 LEFT OUTER JOIN을 하였어요.
이렇게 문제가 해결 되는 듯 하지만 두 방식은 공통 적인 문제가 있습니다.
바로 카사디안 곱으로 중복 된 결과를 보여주게 됩니다.
3. 중복 문제 해결
일단 중복 문제가 실제로 일어나는지 테스트 해봐야해요!
다음과 같이 유저의 컴퓨터를 추가할 때 맥북도 추가를 해보도록 합시다.
우리는 모든 테스트에 10개의 컴퓨터를 확인하도록 하였는데요.
모든 유저당 한 개의 컴퓨터, 한 개의 맥북이 있으니 모든 컴퓨터 이름을 조회한다면 총 20개의 리스트가 있어야 해요.
하지만 테스트 케이스 결과는 그렇지 않습니다.
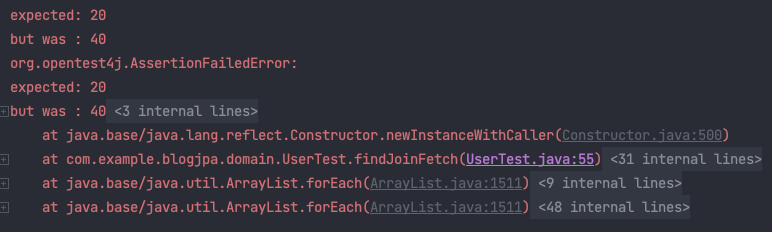
실제로 어떤 값들이 들어가 있는지 확인해볼까요?
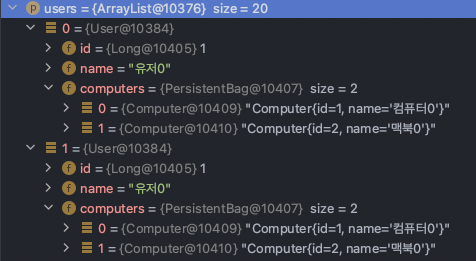
보시는 바와 같이 유저0이 2번 조회 된 것을 확인할 수 있어요. 바로 카사디안 곱이 적용이 된 것입니다.
그렇다면 이 문제는 어떻게 해결할까요?
바로 중복 제거인 Distinct를 사용 하면 돼요.

두 메서드의 JPQL 쿼리에 DISTINCT 키워드를 넣어주었습니다. 다시 테스트케이스를 실행 해 보겠습니다.
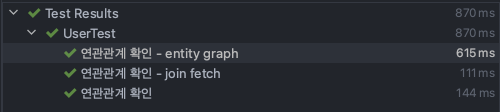
모두 통과하였습니다. 그리고 다른 방법은 없을까요?
바로 쿼리의 결과를 Set Collection에 담는 것입니다. Set은 중복을 허용하지 않기 때문에 중복 된 데이터들을 Collection에 포함이 될 수 없습니다.
결과를 볼까요?

마찬가지로 모든 테스트가 통과 되었습니다. 개인적으로 Set 자료구조를 이용하겨 된다면 결국 데이터를 가져오는 부분에서 카사디안 곱이 적용 된 데이터를 가져오게 되지 않을까? 하는 생각이 드는데요. 두 방법을 고민하셔 적용을 시키면 될 거 같습니다.
4. 마치며
이상으로 N+1 문제를 알아보았는데요. N+1이 어떻게 발생 될지 예측하고 테스트케이스를 꼼꼼히 작성하여 예상 외의 결과에 대해서도 방어가 되는 코드를 작성하는 것이 좋겠다고 느꼈습니다.
감사합니다!
'Java' 카테고리의 다른 글
| 제네릭에 대한 간단한 정리 (0) | 2021.10.06 |
|---|---|
| Java의 Call by value, Call by reference (0) | 2021.08.09 |
| 간단한 Spring AOP 개념과 적용 (0) | 2021.07.30 |
| 간단하게 상속과 조합을 이해해보기 (0) | 2021.07.26 |